
TinyML — short for Tiny Machine Learning — refers to running machine learning models directly on small, ultra-low-power devices like microcontrollers. While “ML” can cover many techniques, today it often points to deep learning. The “Tiny” part highlights the magic: taking something that usually runs on powerful computers and shrinking it down to work on hardware with just a few hundred kilobytes of memory.
These embedded devices come in all shapes and sizes. On one end, you have advanced edge platforms like the NVIDIA Jetson Xavier AGX — practically a supercomputer for AI at the edge. On the other, you’ll find tiny microcontrollers like the ESP32 or Cortex-M0, which sip power and can fit almost anywhere. ESP32 TinyML Benchmark focuses on making intelligent features possible even on these smallest, most constrained devices.
TinyML on microcontrollers like the ESP32 is unlocking on-device AI for always-on sensing, voice control, and low-latency detection. But a model that “works” functionally may still be impractical if it drains batteries too fast. That’s where Energy-Aware TinyML on ESP32 becomes essential: it measures not only accuracy and latency, but the actual energy cost per inference and end-to-end system behaviour on the ESP32 hardware. In this article I’ll explain why energy-aware benchmarks matter, summarize the newest study results, show how to measure energy in practice, and give actionable optimizations so your TinyML project can run longer in the field.
Why energy-aware ESP32 TinyML Benchmark matters?
Traditional ML benchmarks focus on accuracy and runtime. For battery-powered edge devices, those metrics aren’t enough — energy per inference and duty-cycle behaviour determine battery life. Recent research highlights that ESP32-class MCUs often consume orders of magnitude more energy for the same task than specialized tiny NPUs, and that choices across preprocessing, sampling rate, and model size strongly affect net energy use. Benchmarking energy explicitly helps you answer questions such as: Is it better to run a larger model less frequently, or a smaller model more often? and Can hierarchical inference (small model on-device + cloud only on uncertainty) save energy overall?
A- How to accurately measure ESP32 TinyML energy consumption? (a repeatable methodology)
Energy benchmarking must be precise and phase-aware. Best practice is to separate the measurement into pre-inference (sensor read + preprocessing), inference (model execution), and post-inference (transmit, logging) phases. Use a high-resolution power monitor (shunt + ADC or a power analyser) and a dual-trigger approach to isolate these phases reliably. Recent benchmarking work recommends the dual-trigger method to make energy and latency numbers repeatable across experiments. Capture energy per phase (µJ or mJ) and wall-clock time (ms) to compute energy per inference and average power. (ResearchGate)
Practical tools: INA219/INA226 + high-sample-rate logger, Otii Arc, or a bench power analyser. Record CPU frequency, PSRAM usage, and whether inference moves data in/out of external memory — these affect latency and energy strongly on ESP32 variants.
B- What the latest studies say about TinyML on ESP32?
Recent papers and benchmarks provide concrete numbers you can rely on:
- A 2025 benchmarking paper shows that ESP32 devices exhibit relatively high inference power (≈130–157 mW) with large variability in latency (7–536 ms) depending on model size and memory usage; this makes the ESP32 practical for small models, but inefficient for larger or memory-heavy networks. (arXiv)
- A dedicated ESP32-CAM benchmark study reports that camera capture, preprocessing, and memory transfers dominate energy when running vision TinyML on ESP32 modules; the implication is that optimizing image resolution and preprocessing can yield large energy wins. (arXiv)
- Research on data-rate reduction and hierarchical inference demonstrates that reducing sampling rates or using a small on-device filter before running heavier models can reduce overall energy while retaining acceptable accuracy for many tasks. This strategy is effective on ESP32-class MCUs where every millijoule counts. (arXiv+1)
These studies underscore a key takeaway: ESP32 is capable for TinyML but you must design at the system level (sensing → preprocess → model → comms) to be energy-efficient.
C- Energy optimization strategies for ESP32 TinyML Benchmark
-
Model selection & compression
Choose compact architectures (tiny CNNs, depthwise separable convs, small dense nets). Use quantization (int8), pruning, and operator fusion to reduce RAM/compute and cut inference energy.
-
Preprocessing & sampling
Lowering camera resolution, reducing sampling rate, or using lightweight signal filters can dramatically reduce pre-inference energy. Studies show that smart sampling often outperforms brute-force model slimming because sensors and memory transfers are major energy sinks. (arXiv+1)
-
Duty-cycle and hierarchical inference
Run an ultra-lightweight detector continuously and trigger a heavier model only on events (motion, sound, anomaly). Hierarchical inference improves accuracy-energy tradeoffs when designed properly. (dspace.networks.imdea.org)
-
Hardware & runtime tuning
Use the ESP32-S3 if possible (better vector instructions for ML), tune CPU frequency, pin peripherals off during sleep, and minimize PSRAM access by keeping tensors in SRAM. Power gating unused radios (Wi-Fi, BT) between transmissions saves substantial energy.
Low-Power TinyML Models on ESP32: Latency & Energy Table
Numbers below are reported ranges from recent benchmarking literature and practical ESP32 experiments; actual values depend on model, input size, and power settings.
|
Platform / Setup |
Latency (ms) |
Energy per inference |
Typical model size |
Best use cases |
|
ESP32 / generic (small model) |
7–50 ms |
~1–10 mJ |
<100 KB |
KWS, simple sensor classification |
|
ESP32 / larger vision (with PSRAM) |
100–500+ ms |
10–150 mJ |
500 KB–2 MB |
Low-fps image classification (careful tuning) |
|
ESP32-S3 optimized (vector ops) |
5–60 ms |
0.5–20 mJ |
50–300 KB |
Faster ML kernels, improved efficiency |
|
μNPU (dedicated accel, e.g., NDP120) |
~4 ms |
~35 µJ (0.035 mJ) |
tiny (few KB weights) |
Always-on KWS, ultra-low energy sensing (for comparison). |
Run TinyML Offline on ESP32 with TFLite-Micro
ESP32 is one of the most popular boards for this because it’s affordable, energy-efficient, and has built-in Wi-Fi/Bluetooth for smart IoT applications. Using TensorFlow Lite for Microcontrollers (TFLite-Micro), you can deploy models that run fully offline, without a cloud or internet connection.
This makes TinyML perfect for real-time, privacy-focused, edge intelligence, such as:
✅ Keyword spotting (“Hello ESP32”)
✅ Gesture or motion recognition
✅ Anomaly detection for machines & sensors
✅ Simple image classification (with ESP32-CAM)
TinyML Workflow on ESP32 (Beginner Diagram)
Here is the complete workflow from training to deployment:
┌──────────────────────┐│ 1) Collect Data │ (sounds, images, sensor signals)└─────────┬────────────┘│▼┌──────────────────────┐│ 2) Train Model │ (TensorFlow / Edge Impulse /│ │ Teachable Machine)└─────────┬────────────┘│▼┌──────────────────────┐│ 3) Convert to TFLite │ (.tflite or .tflite-micro)│ & Quantize │ (int8 for small memory)└─────────┬────────────┘│▼┌──────────────────────┐│ 4) Deploy to ESP32 │ (TensorFlow Lite-Micro + Arduino IDE)│ + Write inference ││ loop in C/C++ │└─────────┬────────────┘│▼┌──────────────────────┐│ 5) Run on-device │ (Real-time inference at the edge)│ + Act on results │└──────────────────────┘ |
TensorFlow Lite is a streamlined version of TensorFlow, optimized for mobile platforms and embedded systems.
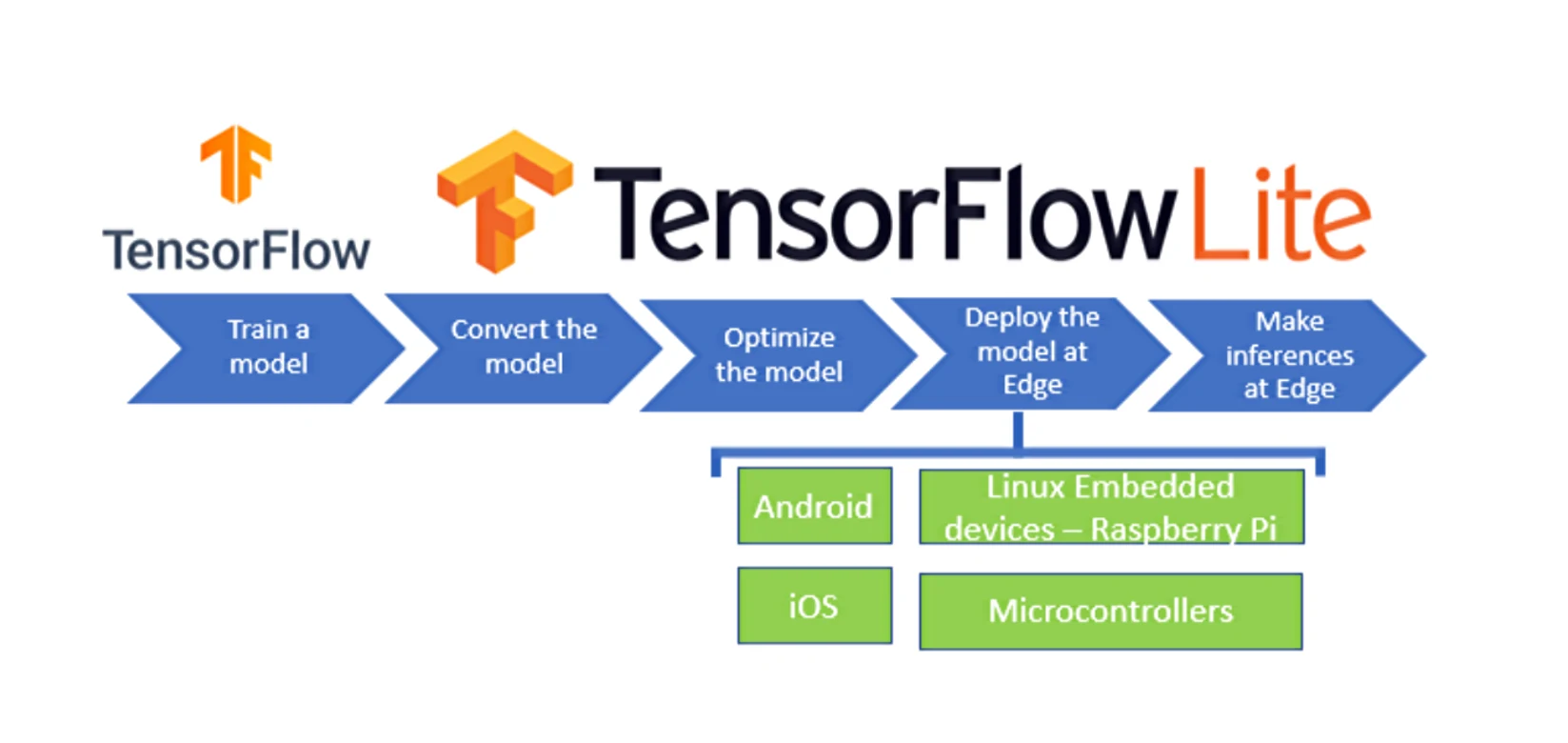
What You Need for Low-Power Edge ML for IoT Devices
| Tool | Purpose |
|---|---|
| ESP32 / ESP32-CAM | Edge hardware running inference |
| TensorFlow or Google Teachable Machine | Model training |
| TensorFlow Lite-Micro | ESP32-compatible ML runtime |
| Arduino IDE / PlatformIO | Deployment and coding |
| Optional: Edge Impulse | Easiest GUI training pipeline |
Tools You Need To Try:

Challenges in TinyML:


Example: What ESP32 TinyML Code Looks Like
Here is a simplified inference loop in Arduino + TFLite-Micro:
|
|
The ESP32 reads data → feeds it into the ML model → and acts locally.
⚡Why TinyML on ESP32 Is Powerful?
| Benefit | Why It Matters |
|---|---|
| No Cloud Needed | Faster response, no server cost |
| Low Power | Battery-friendly for IoT |
| Real-Time | Great for control, robotics, sensing |
| Privacy | Data stays on-device |
Practical checklist to run energy-aware benchmarks on ESP32
- Isolate phases (sensor, preprocess, inference, transmit) with triggers. (ResearchGate)
- Measure at the power rail with a 10 kHz+ sampling instrument.
- Report energy per inference (µJ or mJ), latency, and memory footprint.
- Test multiple clock speeds and sleep strategies.
- Repeat with representative workloads (real sensor traces, not synthetic inputs).
Conclusion
ESP32 remains one of the most practical, low-cost platforms for TinyML experimentation — but energy efficiency is not automatic. The newest benchmarks show that while small models run well, larger vision models and memory-intensive workloads cause large energy and latency penalties on ESP32. By adopting energy-aware benchmarking practices (phase isolation, precise measurements) and Energy-Aware TinyML on ESP32 system-level optimizations (sampling, hierarchy, quantization, and runtime tuning), you can deliver TinyML applications that are both accurate and battery-friendly.
If you’re prototyping TinyML on ESP32, start small, measure everything, and design for the full sensing→compute→comms pipeline — the battery life payoffs are often larger than the last 1–2% of accuracy. For further reading, check the cited benchmark and TinyML studies above to ground your experiments in real measurement data.
Explore the latest ESP32 boards and modules in the Siqma store and kick-start your next IoT or TinyML project today.





